Lars Borin och Richard Johansson
Vilka vetenskapliga frukter kan vi skörda av de ansträngningar som gjorts att digitalisera text från olika tidsepoker? En av möjligheterna som öppnas är att kvantitativt studera hur språket i materialet förändras över tiden. Detta ger oss förstås en bild av hur själva språket förändras men även av hur händelser i världen och samhället påverkar det som skrivs. I en omtalad artikel i Science (Michel et al. 2011) beskriver ett forskarlag från Google och några universitet hur man kan utnyttja de stora mängder böcker som Google har digitaliserat för att göra storskaliga kvantitativa undersökningar av språklig och kulturell förändring över perioden 1800–2000. Studien lanserades under rubriken culturomics – kulturomik – i analogi med genomics och proteomics, beräkningstunga, massivt databeroende ansatser inom molekylärbiologi.[1]
Kulturomikartikeln ledde till en livlig metoddiskussion, där man bland annat påpekade att författarna verkade helt ovetande om de språkliga aspekter som skulle behöva hanteras när man skalar upp den här typen av undersökning från traditionell mänsklig ’närläsning’ till helautomatisk bearbetning av stora textmängder.[2] En människa som behärskar språket har inga problem med att föra samman olika böjningsformer eller stavningsvarianter av samma uppslagsord (t.ex. förstå att telegrafen och telegrafer hör hemma under telegraf), att skilja homonymer åt (t.ex. inse när friser anger ett folkslag och när det handlar om ett slags utsmyckningar) eller att tolka när situationer beskrivs från olika utgångspunkter (t.ex. ha klart för sig att när man säger att misstag har begåtts vill man förmedla en annan bild av det skedda än om man säger att vi har begått misstag).
I de metodologiska anmärkningarna döljer sig dock en möjlighet. Den ursprungliga kulturomikundersökningen förfogade över ett enormt material, nästan 5,2 miljoner böcker eller över 500 miljarder ord. Även det minsta delmaterialet, det hebreiska (som inte användes alls i artikeln), omfattade c:a 2 miljarder ord. Detta är viktigt, eftersom låg grad av språklig analys i viss mån kan kompenseras av att man har ett mycket stort material. Omvänt kan man förvänta sig att bra verktyg för automatisk språkanalys kan göra att man uppnår jämförbara resultat även med mindre materialmängder. Detta är en av förutsättningarna för ett svenskt kulturomikprojekt som bedrivs med ett rambidrag från VR (Borin et al. 2013).[3] Nedan diskuterar vi de möjligheter vi ser när det gäller att utföra den här typen av studier på svenskspråkigt material.
Språkbankens textsamlingar och sökverktyg
Språkbanken (http://spraakbanken.gu.se) är en forskningsenhet vid institutionen för svenska språket på Göteborgs universitet. En av Språkbankens viktigaste verksamheter är att samla in svenskspråkiga textsamlingar (korpusar) och lexikonresurser, och göra dem tillgängliga för allmänheten. Dessa resurser kommer från en rad olika tidsperioder, från de äldsta medeltida lagtexterna fram till nutida material som nyhetstexter och texter från sociala medier.
Många av Språkbankens korpusar innehåller information om texternas tillkomsttid. Detta gör det möjligt att söka i materialet och studera hur det förändras över tiden. Ett intressant exempel på detta är KB-materialet, ett omfattande textmaterial som kommer ur Kungliga bibliotekets skorskaliga digitalisering av historiska dagstidningar. Hittills har en stor mängd svenskspråkigt tidningsmaterial från sent 1700-tal fram till tidigt 1900-tal digitaliserats. Tidningstexterna kommer från 20 olika tidningar, framför allt landsortstidningar, och huvuddelen av materialet är från andra halvan av 1800-talet. Materialets exakta omfång i ord är svårt att ange på grund av ojämn kvalitet i digitaliseringen (se nedan), men det handlar om knappt 48.000 tidningsnummer omfattande totalt omkring 700 miljoner ord.
För att söka i Språkbankens textsamlingar används sökverktyget Korp (http://spraakbanken.gu.se/korp). Detta verktyg kan användas till exempel för att söka efter enstaka ord eller ordkombinationer och deras sammanhang (konkordans) och för att jämföra ords frekvenser. För den som är intresserad av språkbrukets förändring över tiden finns möjligheten att använda trenddiagram, som visar ordens förekomstfrekvenser år för år. Nedan visar vi ett antal användningar av trenddiagrammen, framför allt genom sökningar i KB-materialet.
Exempel på enkla tidssökningar
Neologismer (nya ord) kan ge oss intressanta perspektiv på den tid där de uppstår. Under 1800-talet sker det en hel del tekniska förändringar i Sverige, vilket vi ser avspeglas i tidningsmaterialet. Några exempel på detta är orden telegraf, telefon och automobil. Telegrafen uppfanns i slutet av 1700-talet och nämndes i den tidens svenska tidningar, men fick ett medialt genomslag först när den blev praktiskt användbar i och med Morses elektriska telegraf från 1837. Telefonen uppfanns av Bell 1876 och blev därefter snabbt populär i Sverige. Ytterligare en teknisk uppfinning från denna tid är automobilen, som förekommer i slutet av perioden.[4] Nedanstående figur visar resultatet av en sökning med Korp i KB-materialet efter dessa tre ord.

Även ur idéhistoriskt perspektiv är 1800-talet intressant att studera på en tidslinje. Till exempel orden kommunistisk, kommunism och kommunist nämns för första gången 1841. Därefter finns det tre perioder då dessa ord förekommer ofta i tidningsmaterialet: under revolutionsperioden runt 1848 (då dessutom Kommunistiska manifestet författades), under perioden runt Pariskommunen 1871, samt en kraftig ökning i slutet av tidslinjen, vilket sammanfaller dels med ryska revolutionen och dels med att det svenska kommunistiska partiet bildades genom en utbrytning från socialdemokraterna.

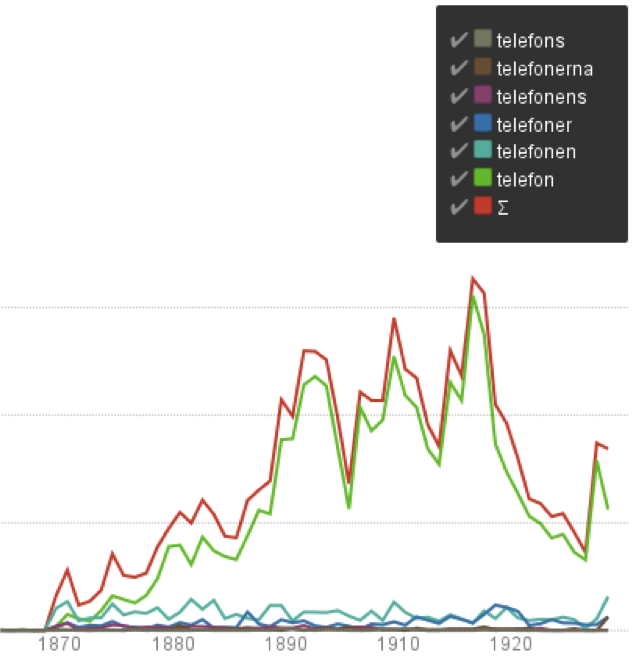
I båda dessa fall har Språkbankens lexikon och språkverktyg använts för att föra ihop textorden till lexikonord. Följande diagram visar hur de olika böjda formerna av ordet telefon förekommer i materialet. Även om formen telefon är absolut mest förekommande, blir det ändå en märkbar skillnad i det sammanlagda antalet förekomster (den översta, röda kurvan: Σ), som avspeglar summan av de olika formernas frekvens. Särskilt när antalet förekomster är lågt, som till vänster i diagrammet, kan den här typen av språklig bearbetning hjälpa oss att få ut mer av materialet.
En annan intressant idéhistorisk tendens under 1800-talet är framväxten av den rasbiologiska forskningen, och detta påverkar också det allmänna språkbruket. För att ta ett exempel kan vi söka efter uttryck av typen rasen föregånget av ett adjektiv. De två vanligaste uttrycken av denna typ i KB-materialet är gula rasen och hvita rasen. Vi ser att sådana uttryck kommer i bruk under andra halvan av 1800-talet, vilket också passar bra ur ett idéhistoriskt perspektiv: detta var efter att Retzius metoder för skallmätning presenterats på 1840-talet och inflytelserika verk som Gobineaus Essai sur l’inégalité des races humaines (1853) och Darwins On the origin of species (1859) publicerats.
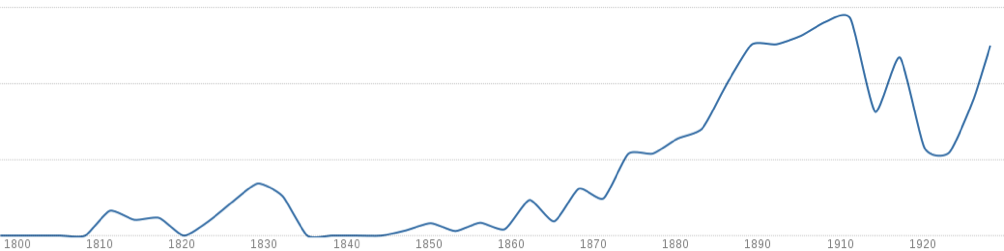
Den uppmärksamme kanske undrar hur det kommer sig att vi ser en topp på 1830-talet. Dessa träffar kommer av felaktigheter i arkiven som beror på misslyckad digitalisering, vilket vi kommer att diskutera i mer detalj nedan.
Språket förändras över tiden, inte bara som vi sett ovan ordförrådet utan också grammatiken. Ett exempel på detta är att svenska verb förr böjdes efter numerus: de hade en singularform (t.ex. jag är) och en pluralform (t.ex. vi äro), liksom flertalet europeiska språk fortfarande har. Pluralformerna försvann ur det svenska skriftspråket i början och mitten av 1900-talet. Denna på sin tid kontroversiella förändring skedde gradvis i skönlitteraturen, medan de flesta tidningar övergav pluralformerna någon gång i perioden 1943–1945. Detta ser vi tydligt i korpusen ORDAT, som består av Svenska Dagbladets årsböcker från åren 1923–1945 samt 1948 och 1958: här sker övergången mellan 1944 och 1945. Vi sökte efter sju av de vanligaste distinkta pluralformerna (äro, voro, kommo, fingo, gingo, sutto, lågo) och resultatet visas nedan.

Relation till humanistisk (och samhällsvetenskaplig) forskning
Man kan invända att exemplen i föregående avsnitt inte tillför någon ny kunskap, utan enbart ytterligare bekräftar vad vi ändå vet på annat sätt. Det är naturligtvis sant, och våra exempel, liksom de som anfördes av Michel et al. (2011) i den ursprungliga kulturomikartikeln, förstås kanske bäst om man tänker på dem ungefär som kalibrering och verifiering av ett mätinstrument. I och med att metoden faktiskt ger rimliga utslag för kända fakta, kan vi med viss tillförsikt ge oss på att använda den för att söka efter ny kunskap, t.ex. mer förutsättningslöst spana efter ord, uttryck och konstruktioner som varierar i användning över tiden. Detta är något som kräver såväl utveckling av metoden i form av mjukvara och användargränssnitt som nära samarbete mellan dem som förstår tekniken och dem som kan formulera forskningsfrågorna: historiker, idéhistoriker, presshistoriker, retorikhistoriker, språkhistoriker, m.fl.
En särskild utmaning ligger här i att utveckla metodologi och verktyg som på ett enkelt sätt låter forskare röra sig mellan kulturomikens storskaliga kvantitativa studier och den traditionella humanistiska forskningens detaljerade närstudium. Som ett litet embryo till detta kan man i Korps trenddiagram klicka på varje datapunkt och i en separat flik få upp en konkordans för just den datapunktens träffar i materialet, som i följande bild, som visar de 47 förekomsterna av telefonen för år 1896 i KB-materialet. Det är inte tekniskt svårt att införa möjligheten att gå vidare till den fullständiga texten från varje konkordansrad.

Tekniska utmaningar
Som vi har sett kan vi göra en hel del intressanta undersökningar, men vilka begränsningar finns det? Vi diskuterar nu några tekniska svårigheter som gör att man får vara försiktig vid tolkningen av sökresultat i äldre textmaterial.
Teckenigenkänning (OCR)
När vi gjorde de teknikhistoriska undersökningarna ovan, varför sökte vi på automobil men inte den moderna varianten bil? Kan vi för övrigt säga när bil blev vanligare? Nedanstående figur visar resultatet av en sökning efter de två varianterna.

Resultatet tycks paradoxalt: bil verkar förekomma under hela 1700- och 1800-talet, trots att denna kortform enligt Svenska Akademiens Ordbok började användas först runt 1900. En inspektion av träffarna visar vad problemet är. Till exempel i Dalpilen 1893 ser vi träffar som bil jätter (biljetter) och bil hörd (bli hörd), vilka båda är uppenbart felaktiga. Detta beror inte på att tidningsskribenterna var slarviga utan på att överföringen från papper till dator inte är felfri. Det känsligaste steget kallas teckenigenkänning eller teckentolkning, på engelska optical character recognition (OCR), och innebär att datorn ska tolka de inskannade bilderna av de tryckta tidningssidorna och avgöra vilka bokstäver de motsvarar. Detta är svårare för äldre text av flera skäl. Gamla tidningsexemplar är tryckta på tunnare och porösare papper så att trycket flyter ut eller slår igenom till baksidan, tidningsexemplaret kan helt enkelt vara slitet, OCR-programmet kan ha en ordlista som inte är anpassad till det äldre språket, och slutligen avkodar alla OCR-program överlag äldre fraktur betydligt sämre än både nyare fraktur och antikva. Vi ser mycket riktigt i KB-materialet att de äldre texterna ofta innehåller en betydligt högre andel feltolkningar.
Så varför får vi så många felaktiga bil men inga automobil? Detta beror helt enkelt på att eftersom bil är ett kort ord så är det lätt att ha otur och få detta ord vid en felläsning. Automobil är längre och det krävs därför betydligt mer otur för att få detta ord av misstag.
Stavningsvariation
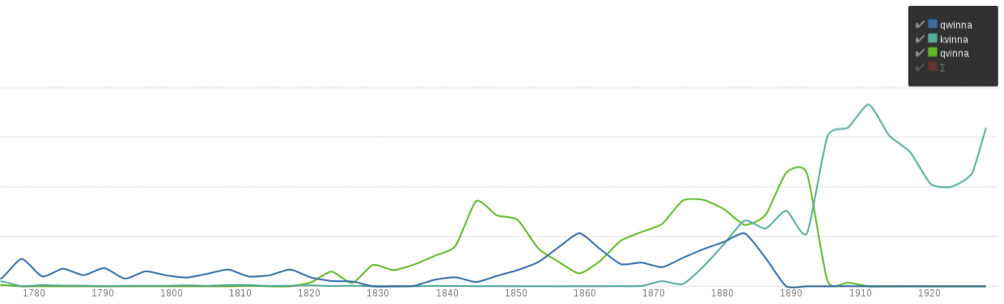
Anta att vi vill studera om ordet kvinna nämndes oftare i tidningarna under den tid då frågor som t.ex. kvinnors rösträtt började diskuteras. En sökning på detta ord i KB-materialet verkar vid en första anblick stödja hypotesen: från 1870-talet och en bit in på 1900-talet ökar detta ords frekvens markant. En närmare inspektion visar dock att vi har något problem med vår sökning eftersom det knappt förekommer någon träff alls innan 1870, och de enstaka som förekommer verkar vara sådana där teckenigenkänningen gått fel.
I det här fallet är förklaringen att ordet kvinna har stavats på flera olika sätt genom tiderna. På 1600-talet (t.ex. i korpusen Stockholms stads tänkeböcker) skrevs det ofta quinna eller qwinna, och om vi går över till KB-materialet (se figur nedan) så dominerar först stavningen qwinna, därefter qvinna, och den moderna stavningen kvinna först i och med stavningsreformerna i början av 1900-talet.
En viktig social förändring som sker under 1800-talet är framväxten av en organiserad och ideologisk arbetarrörelse, och spåren av detta kan vi också studera i den tidens tidningar. Det leder oss till ett annat ord vars stavning har varierat över tiden, nämligen strejk. I detta fall beror svårigheten på att det tagit ett tag innan stavningen av detta lånord stabiliserats. Strejker börjar nämnas i svenska texter under mitten av 1800-talet. I början används den engelska stavningen strike; stavningen strejk tar över på 1870-talet. Alternativet sträjk levde kvar en bit in på 1900-talet.

Hur kan man göra det möjligt att genomföra sökningar av denna typ för den som inte är språkhistoriskt bevandrad? Språkbanken tillämpar två olika metoder för att hantera detta problem. Den första metoden är att använda diakroniska lexikon: ordlistor där vi helt enkelt kan slå upp att ordet kvinna tidigare har stavats quinna, qwinna, och qvinna (Borin och Forsberg 2011). Därmed kan vi även automatiskt ta med ordens alla stavningsvarianter i sökningarna. Detta fungerar väl när det gäller tidigmodern text, t.ex. från 1800-talet som i KB-materialet, då det förekommer ett litet antal standardformer. Den andra metoden baseras på ungefärliga ordjämförelser: vi kan säga att ett textord qwenna förmodligen motsvarar lexikonordet quinna eftersom qw är en stavningsvariant av qu, och ljudet e ligger nära i. Denna metod kan tillämpas vid analys av äldre text, t.ex. från medeltiden, där det inte ens är meningsfullt att tala om standardformer och antalet varianter är stort (Adesam, Ahlberg och Bouma 2012).
Lingvistiskt komplexa sökningar
De undersökningar vi hittills har visat har haft den begränsningen att de baserats på förekomst av enstaka ord, men det finns många sätt man skulle vilja undersöka frågeställningar som inte så lätt låter sig brytas ned till enkla ordsökningar. För att möjliggöra mer komplexa undersökningar finns en hel del olika lingvistiska analysverktyg.
Om vi till exempel vill undersöka vad man åt på 1800-talet (eller åtminstone vad tidningarna skriver om ätande) kan vi söka på förekomster av verbet äta och se vilka substantivobjekt det samförekommer med. För nutida material är detta relativt oproblematiskt: om vi till exempel söker i Göteborgsposten mellan 2001 och 2012 så ser vi att de vanligaste sakerna som man äter är lunch, middag, kött, frukost och fisk. För att avgöra vilket som är verbets objekt använder vi ett syntaxanalysverktyg (på engelska parser), och en ordklassmärkare kan avgöra om ordet är ett substantiv. Andra möjligheter är till exempel att använda en namnuppmärkare för att avgöra vilka typer av person- och ortnamn som omnämns.
Dessa lingvistiska analysverktyg är baserade på moderna ordlistor samt ordstatistik som insamlats genom att observera moderna texter, och att de är byggda för modernt språk gör att de har svårt att hantera äldre texter (Pettersson, Megyesi och Nivre 2012). Detta ser vi när vi söker på äta och dess objekt i KB-materialet. De vanligaste korrekta substantiven som vi hittar är middag, frukost, kött, bröd och gräs, alltså nästan detsamma som i det moderna materialet, men i topplistan finns också en hel del felaktigheter. Till exempel ser vi adverbet deraf (därav), vars stavning ställer till problem för ordklassmärkaren, och ett antal OCR-relaterade problem, exempelvis stall (från åter skall) stola (från åter skola). Metoder för att hantera språkliga genreskillnader (domänanpassning) är ett område som på sistone fått mycket uppmärksamhet inom den språkteknologiska forskningen, och det återstår att se om dessa metoder också kan användas för att hantera språkliga skillnader som beror på språkförändring över tid.
Sammanfattning
Textsamlingar där texterna innehåller information om tillkomsttid öppnar nya möjligheter för kvantitativa studier av språkhistoriska, kulturhistoriska och idéhistoriska frågor, med den nya forskningsmetodologi som kallas kulturomik. Detta ställer dock krav på att det finns användbara sökverktyg för att söka i den typen av samlingar på ett överskådligt sätt, och leder också till en hel del tekniska utmaningar och öppna forskningsproblem inom t.ex. teckenigenkänning, hantering av stavningsvariation, samt anpassning av språkteknologiska verktyg till äldre tiders språk.
Referenser
Yvonne Adesam, Malin Ahlberg och Gerlof Bouma (2012). bokstaffua, bokstaffwa, bokstafwa, bokstaua, bokstawa… Towards lexical link-up for a corpus of Old Swedish. Proceedings of the 11th conference on natural language processing (KONVENS), 365–369. Wien: ÖGAI.
Lars Borin, Devdatt Dubhashi, Markus Forsberg, Richard Johansson, Dimitrios Kokkinakis och Pierre Nugues (2013). Mining semantics for culturomics: Towards a knowledge-based approach. Proceedings of the 2013 international workshop on mining unstructured big data using natural language processing, 3–10. New York: ACM. http://dx.doi.org/10.1145/2513549.2513551.
Lars Borin och Markus Forsberg (2011). A diachronic computational lexical resource for 800 years of Swedish. Caroline Sporleder, Antal van den Bosch och Kalliopi A. Zervanou (red.), Language technology for cultural heritage, 41–61. Berlin: Springer.
Jean-Baptiste Michel., Yuan Kui Shen, Aviva Presser Aiden, Adrian Veres, Matthew K. Gray, The Google Books Team, Joseph P. Pickett, Dale Hoiberg, Dan Clancy, Peter Norvig, Jon Orwant, Steven Pinker, Martin A. Nowak och Erez Lieberman Aiden (2011). Quantitative analysis of culture using millions of digitized books. Science 331: 176–182.
Eva Pettersson, Beáta Megyesi och Joakim Nivre (2012). Parsing the past – Identification of verb constructions in historical text. Proceedings of the 6th EACL Workshop on Language Technology for Cultural Heritage, Social Sciences, and Humanities, 65–74. Avignon: ACL.
Läs också:
Big data
av Kenneth Nyberg
Fördjupning: Digitala textarkiv och forskningsfrågor
av Mats Malm
Fördjupning: Open research methods in computational social sciences and humanities: introducing R
av Markus Kainu
[1] Se även http://www.culturomics.org.
[2] Se t.ex. Mark Libermans artiklar på Language Log:
http://languagelog.ldc.upenn.edu/nll/?p=2848 och
http://languagelog.ldc.upenn.edu/nll/?p=4456.
[4] De teknikhistoriska detaljerna är hämtade från Tekniska museets webbsidor: http://www.tekniskamuseet.se.

Pingback: Kluster, ninjor och hämtpizza – Lärdomar från universitetet
Pingback: Användning av kvantitativa metoder | Digital humaniora
Pingback: Om digitala kvantitativa metoder stödjer historieforskning eller försämrar dess kvalitet beror på hur man som forskare uppfattar dess roll | franflahistoria
Pingback: Om kvantitativa forskningsmetoder | Digital kultur i humaniora
Pingback: Kvantitiva metoder inom historieforskning | digikulturblogg
Pingback: Fördjupning: Kulturomik: Att spana efter språkliga och kulturella förändringar i digitala textarkiv | Historia i en digital värld