Texten i detta kapitel är, när inget annat anges, författad av Jessica Parland-von Essen och Kenneth Nyberg. Kapitlet är fortfarande under arbete och består för närvarande av följande avsnitt:
- Arbetssätt, verktyg och metoder
- Att strukturera information
- Att arbeta med databaser
- Big data
- Fördjupning: Fjärrläsning och närläsning, stordata och smådata
- Fördjupning: Digitala textarkiv och forskningsfrågor
- Fördjupning: Kulturomik: Att spana efter språkliga och kulturella förändringar i digitala textarkiv
- Noter
* * *
Arbetssätt, verktyg och metoder
Kenneth Nyberg
Digitala forskningsmetoder kan handla om undersökning, bearbetning, presentation och spridning av material och/eller resultat. Principiellt sett kan vi skilja mellan metoder som hjälper forskaren att snabbare eller mer effektivt göra något som skulle gå även utan digitala verktyg, och sådant som blivit möjligt (eller åtminstone realistiskt) först med hjälp av sådana verktyg. I praktiken är det inte så lätt att göra den gränsdragningen helt exakt, och det går också att diskutera vad som ska ses som något kvalitativt nytt eller inte, men distinktionen är ändå viktig.
Strikt talat består metoden i ett visst projekt av ett helt upplägg där olika arbetssätt och resurser relateras till material, teorier och andra faktorer. I mycket av det som följer handlar det alltså inte om digitala metoder i egentlig mening utan om digitala verktyg eller resurser vilka är en del av forskares valda metod. Tyngdpunkten kommer att ligga på just forskningsmetoder i snäv bemärkelse, men som vi framhöll redan i inledningen har digital teknik gradvis kommit att dominera även forskares “vardagsverktyg”. Liksom de flesta i vårt samhälle idag använder historiker sedan länge datorutrustning (inklusive mobila enheter av olika slag) för de flesta rutinmässiga uppgifter som ordbehandling, informationssökning och kommunikation.
Internet i allmänhet och epost i synnerhet fick alltså fäste i den akademiska världen mycket tidigt, långt innan nätet fick mer allmän spridning i mitten av 1990-talet. Forskare har i flera decennier varit aktiva på webbaserade diskussionslistor och deras föregångare (Usenet osv.), och mejl är sedan länge viktigt för kommunikationen både i närmiljön och mellan forskare som arbetar på olika håll i världen. På senare tid har också mer kraftfulla verktyg för samarbete och kommunikation dykt upp, till exempel Google Docs (numera Google Drive) för kollaborativ redigering av dokument i realtid, olika textbaserade chatt- och meddelandetjänster eller Skype för nätbaserade ljud- och videosamtal.[1] I ett senare kapitel återkommer vi till den växande betydelsen av bloggar och (andra) sociala medier som kontaktytor, både inom den akademiska världen och mellan forskarna och det omgivande samhället.
Till kategorin vardagsverktyg hör också dataprogram för att hålla ordning på käll- och litteraturreferenser, där de mest spridda för närvarande är EndNote och Zotero.[2] Långtifrån alla historiker använder sådana program, men för några har de blivit ett viktigt arbetsredskap.
Resten av detta kapitel kommer dock att behandla metodologiska verktyg och praktiker i mer egentlig mening, där det ofta – men inte alltid – på olika sätt handlar om big data, de möjligheter vi har idag att bedriva forskning som bygger på bearbetning av stora datamängder. Ett av de grundläggande kännetecknen för den digitala eran är ju just det gigantiska och ständigt växande flödet av data, vilket kan ses som ett problem: Hur ska vi välja? Hur ska vi orientera oss? Men datamängderna gör det också möjligt för oss att få fram mönster, och därmed ställa frågor, som tidigare varit oåtkomliga för forskningen. Och vi kan göra det tack vare alltmer kraftfulla räknemaskiner, computers, som förmår bearbeta material av sådan omfattning att det ligger långt bortom gränserna för mänsklig förmåga.
Den tekniska utveckling som lett fram till dessa möjligheter brukar inom digital humaniora spåras tillbaka till (åtminstone) 1940-talet, och det finns direkta föregångare till dagens digitala historia i den dataintensiva och kvantitativt inriktade socialhistoria som fick sitt stora genombrott ett par decennier senare. Föga förvånande användes den typen av metoder först i befolkningsstudier och annan forskning där grundmaterialet består av siffror. Det som hänt på senare år är att detta, i någon mening, kvantitativa förhållningssätt nu tillämpas även på frågor som ofta uppfattas som kvalitativa till sin karaktär, det vill säga vi använder data till att visa på mönster i kvaliteter, egenskaper, snarare än i antal och populationer.
Tack vare digital teknik har det också blivit möjligt att på andra sätt än tidigare skapa olika former av visualiseringar av dessa mönster och relationer i materialet. Sådana handlar inte bara om att förmedla forskningsresultat på ett mer överskådligt sätt, även om de kan ha den funktionen också, utan visualiseringar kan utgöra en metod i sig eller fungera som ett verktyg för att kunna ställa frågor av en typ som helt enkelt inte fullt ut kan representeras i textform. Jämte big data kan visualiseringar därför ses som en av de viktigaste aspekterna eller tendenserna inom digital historia och digital humaniora, och båda utgör på olika sätt återkommande teman i detta kapitel.
Att strukturera information
Jessica Parland-von Essen
En viktig sak att beakta då det gäller forskning och en digital forskningsprocess är att information som finns i ett datasystem alltid är strukturerad på något sätt. Den kunde vara strukturerad på olika sätt, men man måste vanligen välja ett. Traditionellt har historiker ofta opererat utifrån ett kronologiskt eller narrativt modus, men dessa faller lätt sönder i den digitala världen eller blir i alla fall endast ett av många tänkbara sätt att organisera och strukturera information. Den struktur man går in för påverkar hur informationen rör sig i systemet och hur den presenteras och också hur vi uppfattar den. Detta måste man först som sist komma ihåg: datorn presenterar information om världen enligt en given tolkning, en modell, som ofta är ett resultat av mängder av medvetna och omedvetna val, ända sedan datorns barndom. Man bör alltså reflektera över hur saker egentligen hänger ihop, då man börjar samla eller arbeta med digitala material. Det vill säga hur saker hänger ihop i verkligheten enligt en själv, och hur de enligt systemet hänger eller borde hänga ihop. Vilka informationsbitar finns och vilka relationer finns det mellan dessa?
Då man under forskningsarbetet samlar på sig digital information, vilket är fallet de flesta gånger idag, är det viktigt att man försöker planera hur man ska organisera och hantera informationen. Ibland kan det finnas behov att samarbeta med it-kunniga personer för att klara av de tekniska utmaningarna och hitta goda lösningar. Det finns framför allt två saker som är avgörande för hur man lyckas med digitala resurser i humanistisk forskning: Den första är tillräcklig planering, den andra är ett kreativt och flexibelt grepp vid förverkligandet av planerna. Trots att det är svårt att förutsäga alla risker och problem måste man verkligen anstränga sig för att planera in i detalj, eftersom det är avgörande för hur man överlag lyckas med forskningen. Det beror på att finansieringen måste vara tillräcklig. Man måste ha en realistisk budget och en långsiktig planering.
Man måste allra först ägna sig åt research vad gäller andra liknande forskningsprojekt och lära sig av andras metoder, misstag och misslyckanden. Viktiga frågor är:
- Hurdan information ska samlas/bearbetas? Detta måste analyseras, struktureras och dokumenteras
- Vad skall göras med informationen?
- Kan man beakta och underlätta eventuell senare återanvändning redan vid struktureringen? Kan den länkas till andra resurser? Finns det liknande material på andra håll som handlar om samma saker?
- Hur hantera frågor om autenticitet och proveniens? (Käll)kritik måste kunna göras både på och under den aktuella forskningen och helst senare också
- Hurdan metadata behövs, på vilken nivå och var ska den finnas?
- Vilka tekniska lösningar finns färdiga att få?
- Hur mycket teknisk utveckling behöver göras?
- Hur kan man säkra hänvisningar och reproduktion av processerna på sikt? Behövs beständiga identifierare (PID) och för vilka saker, eller kan man hänvisa till externa PID?
- Hur kan materialet och själva mjukvaran bevaras (backup) och återanvändas (tillgängliggöras) – också på lång sikt?
- Hur skall arbetet läggas upp? Ansvar, tidtabeller och arbetsfördelning
- Vad kan gå fel? Vilka risker, brister finns eller kan uppstå?
- Fundera på rättighets- och integritetsfrågor. Avtala klart och tydligt om dessa.
- Fundera noga över hur olika lösningar påverkar forskningsmetoden och resultaten
Det skulle vara mycket önskvärt att också forskare inom humaniora skulle erbjuda all data de samlat och använt fritt på webben inklusive all dokumentation. Om man arbetar med modernare material måste man beakta upphovsrätts- och integritetsfrågor; information om människor kan inte samlas, lagras eller publiceras hur som helst.[3] Förutom att noggrann planering och dokumentation är bra för att man på så sätt ger möjlighet för andra forskare att verifiera resultaten, bidrar man också till annan forskning genom att erbjuda källmaterial. Också av denna orsak måste man ha en bra dokumentation av själva systemet och vad det innehåller.
En viktig aspekt, utöver att kartlägga andra liknande projekt och de modeller och standarder som använts i dem, är dessutom att fundera över om man kan utnyttja redan existerande data på annat håll. Går det att berika den egna informationen genom att länka till andra resurser? Sådant kan göras på många sätt. Det kallas länkad data (linked data) och kan ge betydande mervärde för den egna eller annan framtida forskning. Kan man till exempel länka i materialet förekommande personnamn till exempel till något auktoritetsregister? För länkning av data finns olika standarder. Geografisk information finns öppet tillgänglig på exempelvis Google Maps, vilket erbjuder möjligheter att med rätt enkel teknik kunna presentera informationen grafiskt på en karta. Sådana lösningar kallas mash up och går ut på att man kombinerar olika resurser och tjänster. Särskilt inom arkeologin har man redan länge använt sig av geografisk information och tredimensionella modeller. Det finns program där man kan lägga kartor och annan information i lager på varandra, vilket kan vara till mycket stor hjälp för att gestalta samband eller processer.
Att arbeta med databaser
Jessica Parland-von Essen
Det finns många olika sätt att strukturera information. Renodlade traditionella relationsdatabaser är ett. I dem ordnas informationen i tabeller, där varje värde får ett eget id, som man sedan hänvisar till i andra tabeller. Gemensamt för dem är att man försöker ordna informationen på ett sådant sätt att den kan hanteras rationellt och effektivt, så att samma uppgift inte upprepas flera gånger utan att man bara kan hänvisa till rätt ställe vid behov. På det sättet förhindrar man till exempel att man måste göra mångdubbelt arbete. Man kommer alltså i ett tidigt skede in på frågor om begrepp och klassificering, som mycket snabbt får konsekvenser för både forskningsprocessen och resultaten. Det är därför viktigt att man undviker tunneltänkande och använder sig av olika ”etiketter” för saker utan att reflektera och analysera varje begrepp. En viktig princip är att hellre sönderdela informationen i för många typer än för få. Det är nämligen alltid enklare att slå ihop information än att i efterhand börja dela och sortera i klasser. Sådant kräver ofta mycket manuellt arbete.
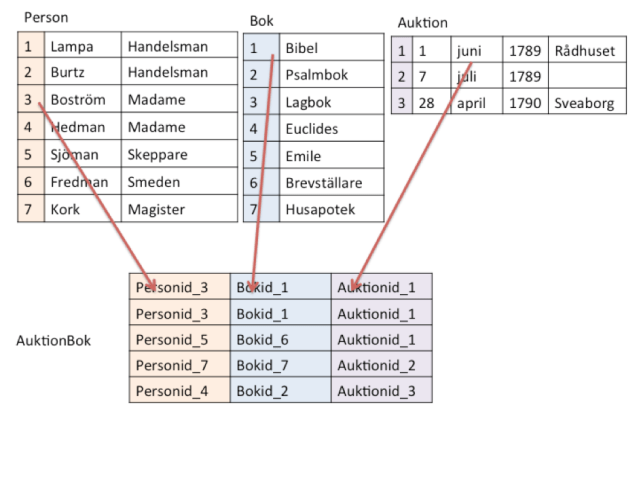
En förenklad, fiktiv version på hur en del av relationsdatabasen bakom den bokhistoriska databasen Henrik ser ut. Här visas att Madame Boström köpt en bibel sommaren 1789 vid en bokauktion i Helsingfors. Informationen i de olika raderna kallas tupler och varje element har fått en egen cell, så att de kan hanteras dynamiskt. Mer om databasen finns på http://dbgw.finlit.fi/henrik/henrik_instruktioner.htm (hämtad 2016-11-26).
Ett system med till exempel en sökvy och en resultatvy och visning av olika sammanställningar av databasens innehåll kan tillsammans utgöra vad man kallar användargränssnitt. Det är ett ställe där ett datasystem möter en människa. Ett vanligt och konkret exempel är en bibliotekskatalog på webben (ofta kallade OPAC, Online Public Access Catalogue), men i praktiken är ju allt man ser på sin skärm strängt taget användargränssnitt. Gränssnitt finns också ofta mellan olika datasystem, där information kan röra sig mellan de olika system. Dessa kallas ofta API, av application programming interface.

Användargränssnitt kallas det verktyg som ger användaren tillgång till databasens innehåll. Innehållet i databasen kan presenteras i olika “vyer” där information presenteras enligt på förhand programmerade anvisningar och de sökfrågor användaren via verktyget skickar till databasen. Skärmdump från Databasen Henrik, http://dbgw.finlit.fi/henrik/henrik_svenska.php (hämtad 2016-11-26).
Många moderna användargränssnitt använder sig ofta av webbkod för att formulera grafiken, men också andra möjligheter finns. För att informationen skall löpa från gränssnittet till det underliggande datasystemet behövs kommandon, sökfrågor eller olika andra skript som berättar för datasystemet vad det ska göra. Ett vanligt språk är SQL, Structured query language, som används i relationsdatabaser. Då man kommunicerar via ett gränssnitt i en webbläsare måste man förpacka SQL-koden i en annan kod; är det andra typer av gränssnitt eller databaser behövs andra språk. Då man använder databaser och datasystem vid forskning är det mycket relevant hur dessa kommandon ser ut. Om man endast sparar rådata räcker det inte för att belägga forskningsresultaten, eftersom exempelvis sökfrågorna (”ta alla enheter som innehåller värdet x och y där värdet för y är mindre än 1790 och räkna dem och visa summan”) de facto är en del av forskningsmetoden, om man går ut med siffran man fått som ett forskningsresultat. Om det i denna kod finns felaktigheter eller brister i logiken kan svaren vara helt felaktiga. Eller snarare är frågorna felaktiga och forskaren får svar på andra frågor än hen tror sig få besvarade. Det betyder att de informationssystem man använt måste dokumenteras noga antingen de bevaras som helhet eller inte.
För att sökningar skall fungera måste man ofta använda sig av normalisering eller tolkning av källorna. Normalisering betyder att man till exempel ändrar i stavningen, så att ord eller namn alltid stavas på samma sätt. Sådant kan ibland vara försvarbart, men man måste komma ihåg att man samtidigt korrumperar informationen i källan. Alltså måste man vara mycket tydlig med att man gjort detta. Det kan vara bra att göra sådant ändå ibland. Tidsuppgifter är en sådan typ av information, att det kan vara försvarbart att av ekonomiska skäl helt kallt normalisera datumangivelser. Då gör man en tolkning redan vid skapandet av den digitala resursen som inte kan kontrolleras annat än mot originalet.
Ett bättre men mer resurskrävande sätt är att ange både den ordalydelse och formulering som finns i originalet och den tolkning som behövs för att uppnå god sökbarhet och funktionalitet. Detta kan lösas genom att ge varje värde ett eget id-nummer som man sedan hänvisar till i samband med uppgiften. Problemet är att det ofta finns en hel del osäkerhet vid identifieringen. Till exempel fanns det i Helsingfors under slutet av 1700-talet två handelsman Lampa, varför det ofta är helt omöjligt att koppla ihop ett viss omnämnande av ”handelsman Lampa” i en källa till en viss person. Ofta kan det vara Clas Lampa lika väl som Carl Lampa. Att hantera denna typ av osäkerhet är svårt i digitala sammanhang. Egentligen bör man hålla de ”verkliga fysiska personerna” skilda från förekomsten av ett namn i en källa, och båda borde ha egna id:n. Dessutom har man ofta ett stort antal namnvarianter att hantera.
Om man lyckas länka sina egna resurser till någon annan resurs på webben, till exempel en ontologi är det särskilt bra, eller om man själv lyckas strukturera sin information på ett sådant sätt. Länkning sker genom att man anger ett id eller helst en beständig webbadress till en särskild uppgift i en annan resurs. En ontologi är en resurs där man organiserat begrepp så att relationerna mellan begreppen finns sparade på ett sådant sätt att en maskin kan använda strukturen till exempel vid sökningar. Ett enkelt exempel är geografiska namn. Ta stadsdelen Hagnäs i Helsingfors, säg att den förekommer i relation till en viss uppgift i ditt material. Säg att du sedan har liknande geografisk information om tusentals andra enskilda uppgifter. Du vill kanske i framtiden jämföra uppgifter från Helsingfors och Ekenäs. För att kunna göra det borde du förutom ”Hagnäs” i informationen också uppge ”Helsingfors” så att uppgiften kan hittas för en jämförelse. Men du vill kanske också jämföra alla uppgifter från Österbotten med alla uppgifter från Nyland. Alltså måste du också ange ”Nyland”. Det betyder att man är tvungen att upprepa samma textsträngar tusentals gånger.
Det säger sig självt att det inte är särskilt effektivt eller rationellt. I stället kunde man ha en annan resurs, en ontologi, där man räknat upp alla ortnamn och hur de förhåller sig till varandra: ”Nyland” = ”Helsingfors” + ”Esbo” + ”Lovisa” etc. Vidare kan man ange att ”Helsingfors” = ”Hagnäs” + ”Sörnäs” + ”Kronohagen” etc. Då räcker det att från varje enskild uppgift i ditt material peka på en enda geografisk information. Datasystemet kan själv räkna ut att om du vill ha alla uppgifter från ”Nyland” hör också uppgiften från ”Hagnäs” dit. Dylika resurser finns och är i många fall tillgängliga på webben. Sådana finns över mängder av olika typer av begrepp på olika språk, vilket ger möjligheter till mycket effektiva sökningar också över språkgränser i vissa fall. När man väljer begreppsontologier måste man analysera dem noga, så att man är säker på att de motsvarar ens världsbild och begreppsapparat. Man bör komma ihåg att ontologierna är tolkningar och modeller av hur världen är konstruerad, inga absoluta sanningar. Det finns kulturella och disciplinära skillnader som kan vara mycket stora. Väljer man en ontologi som ur ens eget perspektiv sett innehåller tankefel, blir kvaliteten av forskningsresultaten lidande!
Då man arbetar med länkad data väljer man ofta numera andra databasstrukturer, där informationen till exempel lagras som enskilda objekt eller grafer av påståenden, som innehåller en specificerad relation mellan olika noder, som i sin tur kan ha olika egenskaper. Det ger dataresurser där det t.ex. går att följa proveniensen för enskilda påståenden noga, vilket är en fördel. Dessutom kan man göra mycket komplexa sökningar och länka informationen till omvärlden med etablerad kod. Då man arbetar med stora datamängder är grafer ofta snabbare och enklare att hantera. Av en välstrukturerad relationsdatabas kan man också skapa en graf att arbeta med.
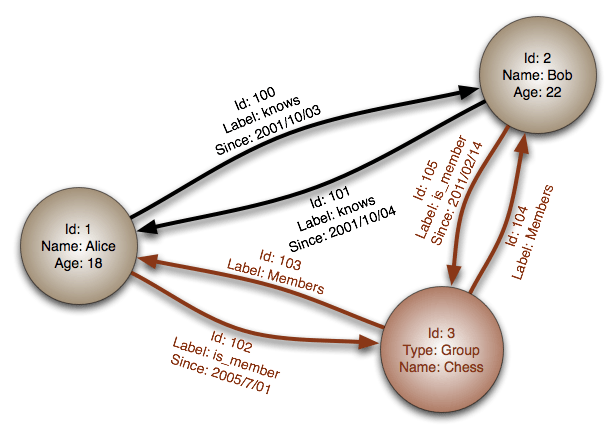
I en grafdatabas presenterar man påståenden om relationer mellan saker och alla element har ett eget id och är hämtade ur en kontrollerad vokabulär. Dessa blir således både komplexa och skalbara. Källa: Wikimedia Commons, https://en.wikipedia.org/wiki/Graph_database#/media/File:GraphDatabase_PropertyGraph.png (hämtad 2016-11-26).
Att konstruera databaser för forskningsändamål är ingen enkel konst. Det kräver vana att skapa modeller av information som är logiskt hållbara och rationella. Sådant utvecklingsarbete kräver nära samarbete mellan forskaren och it-programmerare och helst också en informationsspecialist. Det finns många olika metoder och verktyg man kan använda när man vill modellera data och planera en databas. Men ansvaret för att se till att det finns tillräcklig teknisk dokumentation är i slutändan forskarens; forskaren själv måste kunna fråga efter den och informationsspecialisten kan möjligen hjälpa till med att definiera vilken dokumentation som är mest relevant.
Ofta finns det kommunikationsproblem mellan it-experter och forskare. I synnerhet humanister är ofta omedvetna om vad som ens i teorin är tekniskt möjligt och de kan därför inte ens be om det. Å andra sidan vet it-experterna inte alltid vad humanisterna egentligen vill göra eller är ute efter, varför de inte alltid kommer sig för att erbjuda olika lösningar. Dessutom är informationsteknologin ett mycket vitt område med otaliga olika typer av kompetenser gällande olika system och typer av programmering. Ingen it-kunnig kan allt. En grundregel är ändå för humanisten i svårare förhandlingssituationer att vad som helst är möjligt att göra i teorin, åtminstone med existerande information. Frågan är bara vad man är beredd att betala för olika lösningar. Oftast har man begränsade resurser och då är det mycket viktigt att kunna samarbeta nära och i god anda med it-experter, trots att det kan vara svårt att hitta ett gemensamt språk ibland. Det lönar sig att alltid be om konkreta exempel och om man själv har förebilder eller goda exempel att visa, ska man göra det! Man måste förklara vart man vill komma och vad man behöver göra.
Då man hanterar mycket stora mängder data finns det alltid en större risk för enstaka fel. Om databaser dessutom lever och fylls på gör man också ofta korrigeringar då man hittar felaktigheter. Databaser är alltså ofta genuina digitala texter i det att de inte kan återges meningsfullt på papper och att de ofta lever och förändras. Text som tagits fram ur sådana system är i ovanligt hög grad konstruktioner, resultat av komplicerade tekniska processer som är helt osynliga för den som bara tittar på skärmen. Bakom den bilden finns många lager av tolkningar som går tillbaka ända till hur man skapat modellen och hur informationen motsvarar den verklighet den avbildar. En viktig fråga är om man skilt på namn och objekt och hur systemet hanterar olika varianter av språkliga begrepp. Finns dessa också representerade i systemet, eller måste den som använder systemet hantera dessa manuellt?
För att vara trovärdig måste information vara kopplad till annan information som berättar om proveniens och kontext. Detta är mycket viktigt då det gäller digital information. Vad, när, vem och framförallt hur är frågor som måste få svar i resursen. Detta måste gälla all information i ett system eller projekt, man måste försäkra sig om att data inte seglar fritt någonstans i systemet utan kontext och historia. Detta kräver i normala fall metadata och användning av beständiga identifierare. Många saker kan också förklaras i vidhängande dokumentation, såsom fältbeskrivningar eller kodningsmanualer, som också måste finnas tillgängliga. Man måste också kunna redogöra för principer vid tolkningar av oklara fall. Det är av största betydelse att sådant dokumenteras under arbetets gång så att man uppnår konsekvens i informationen och ger möjlighet till källkritiska bedömningar.
Ofta händer det dessutom att man använder assistenter vid inmatning eller bearbetning av data. Detta kan ibland vara förrädiskt om man inte följer upp arbetet mycket noga, eftersom det i själva verket många gånger kan vara helt avgörande för forskningens slutresultat hur en enskild assistent resonerat i tolkningsfrågor. Om man sedan dessutom använt sig av flera olika personer för arbetet utan mycket noggrann kollationering eller dokumentation, kan man plötsligt ha ett forskningsmaterial av sämre kvalitet än man tänkt sig. Utgångspunkten måste därför alltid vara att man framskrider iterativt, det vill säga stegvis, och i synnerhet i början måste man vara färdig att också ta några steg tillbaka emellanåt och göra om eller komplettera något. Även ett rutinarbete som kodning kan bli mer intressant och givande för den som gör det, vilket ju måste anses som ett plus för alla parter.
Det behövs oändligt mycket kommunikation mellan alla involverade parter och många gånger också teknisk personal. Det är å andra sidan ett minus: räkna med oändliga möten och diskussioner om olika små detaljer – kom då ihåg att varje detalj kan vara av mycket stor principiell betydelse och att det är viktigt att eftersträva konsekvens. Det är i synnerhet detta som avses med att man måste vara kreativ och flexibel vid genomförandet av arbetet. Trots att man satt mycket tid på planering, måste man vara inställd på att planerings- och utvecklingsarbetet fortsätter under hela projektet. Man måste ständigt ta ställning till nya frågor och kanske till och med revidera sina planer. Kill your darlings kan vara den enda lösningen ibland, om något visar sig för dyrt eller ta för lång tid. Då gäller det att vara kreativ.
Big data
Kenneth Nyberg
Big data, “stordata”, ses ibland som en samlande term för mycket av det som är nytt med digital humaniora – eller för den delen det digitala samhället i stort. Enkelt uttryckt är de nya möjligheterna att utnyttja gigantiska datamängder en följd av dels tillgången på data i digital form (vare sig dessa är digitalbaserade eller digitaliserade), dels de alltmer kraftfulla datorer (computers, räknemaskiner) vi har till vårt förfogande för att bearbeta dessa data. Denna uppskalning av beräkningskraften är så omfattande och går så snabbt att man kan tala om en radikal förändring av vilken typ av frågor vi kan ställa oss och rimligen förvänta oss att få svar på.[4]
Följaktligen uppfattas framväxten av digital humaniora inte sällan som en förskjutning från en tyngdpunkt på kvalitativa metoder till en dominans för kvantitativa sådana. Inte minst inom historieämnet har just uppdelningen i kvalitativa kontra kvantitativ metoder ofta betraktats som grundläggande, där det stora genombrottet för de sistnämnda under 1960- och 70-talen inte välkomnades av alla ”traditionellt” arbetande historiker. Efter den s.k. kulturella eller språkliga vändningen inom ämnet under 1980- och 90-talen kan det tyckas som att pendeln nu är på väg att svänga ännu en gång, och vissa konfliktlinjer från den tidigare debatten om kvantitativa metoder kan återigen urskiljas i diskussionen kring digital humaniora.
Det ligger säkert något i dessa positioneringar, vilka avspeglar att forskare har olika prioriteringar och är intresserade av delvis olika saker i sitt studium av det förflutna. Samtidigt ska man inte överdriva motsättningen mellan kvalitativ metod å ena sidan och kvantitativ å den andra; snarare handlar det om en skala utan några skarpa övergångar, ett spektrum där ett givet tillvägagångssätt kan placera sig närmare ena änden och en annan metod hamnar närmare den andra. En gemensam nämnare för nästan all forskning är, trots allt, att hitta mönster i data, att urskilja en signal i bruset, men det kan göras på olika sätt.
Det är också missvisande att kalla mycket av det som för närvarande väcker mest uppmärksamhet inom DH för ”kvantitativ metod” i traditionell mening eftersom det ofta handlar om exempelvis text mining (se nedan) snarare än renodlade statistiska analyser. De nya verktygen används dessutom i många fall för att hitta intressanta ingångar i materialet snarare än för att skapa beräkningar vilka i sig ses som forskningens slutresultat. Detta arbetssätt, där man systematiskt växlar mellan empiri och teori, dvs. data och tänkandet kring data, kallas ibland för abduktion, vilket skiljer sig från induktion där man drar slutsatser utifrån empiriska data och deduktion där man formulerar hypoteser och teorier vilka sedan testas mot empirin.[5]
Med allt detta sagt kvarstår det faktum vi började med, att en stor del av möjligheterna med DH – åtminstone som de uppfattats fram till ganska nyligen då en motreaktion börjat skönjas – på många sätt är kopplade till användningen av stora datamängder. Dels sker det i form av utveckling av konventionella statistiska metoder som ”bara” handlar om mer data och snabbare datorer, dels om helt nya arbetssätt som snarare handlar om kvantifiering av kvaliteter, dvs. att analysera egenskaper och relationer på grundvalen av mycket stora material. Nära förknippad med båda dessa utvecklingslinjer är ytterligare en central företeelse inom DH, nämligen visualiseringar, vilka behandlas i nästa avsnitt. Statistik i sig går vi inte in på i detta sammanhang men några ord behöver sägas om det som kallas text mining, vilket också kommer att tas upp i separata fördjupningsartiklar.
Text mining är en tillämpning av idén om ”big data” på stora textmängder, snarare än exempelvis sifferdata. Det handlar om hur man med hjälp av såväl kvalitativ som kvantitativ databehandling kan analysera stora mängder digital(iserad) text, vare sig det är historiska eller litterära källor. En enkel form av text mining är att i stora korpusdatabaser (av korpus, textsamling) söka efter frekvensen av olika ord och hur den har förändrats över tid. Det går också att studera korrelationer av olika slag, i vilka sammanhang begrepp har använts historiskt (som det avspeglas i de analyserade texterna), vilka ord som tenderar att förekomma nära varandra och så vidare. Kvantitativa studier av stora mängder litterära texter kallas distant reading, där den italienske forskaren Franco Moretti – nu verksam i USA – är en pionjär, och topic modelling är en benämning på analyser av texters tematiska struktur som bygger på studiet av vilka begrepp som används, i vilka sammanhang de förekommer och hur de relaterar till varandra.[6]
Ett känt och omdiskuterat tidigt projekt som bygger på text mining kallas Culturomics och använder sig av de miljontals böcker som Google digitaliserat, där man genom frekvensmätningar försöker studera kulturella förändringar av olika slag.[7] Vem som helst kan också göra enkla sådana analyser i databasen genom webbapplikationen Google Books Ngram Viewer (ofta förkortat ”Google Ngrams”). Den typen av studier kan vara mycket fruktbara, men som många har påpekat är det viktigt att fundera på vad de egentligen säger om djupare betydelser eller större historiska sammanhang och inte ”bara” om orden eller tecknen i sig. Dessutom är det just i Googles fall ofta svårt att veta vilken datamängd det egentligen är man söker i, då den hela tiden förändras i en process som inte är särskilt genomskinlig. Ett exempel på verktyg för topic modelling som fått viss uppmärksamhet är Paper Machines av Jo Guldi, vilket rent tekniskt är en insticksmodul till referenshanteringsprogrammet Zotero.[8]

Google Ngrams. Sökning i Google Ngrams som visar frekvensen av orden computer, digital och history mellan 1958 och 2008 i den engelskspråkiga delen av verktygets korpus, vilken totalt består av flera miljoner böcker på olika språk utgivna mellan 1500 och 2012. (Källa: Google Books Ngram Viewer, http://books.google.com/ngrams, hämtad 2016-12-05.)
I Sverige var det länge främst språkvetare och litteraturforskare som arbetade med text mining, även om historiker också börjat använda sig av sådana och liknande metoder.[9] En viktig resurs i det sammanhanget är Språkbanken vid Göteborgs universitet, en databas med svenska texter som innehåller ca en miljard ord och sträcker sig flera hundra år tillbaka men också innehåller material från ett antal nutida svenska bloggar. Andra svenska korpusdatabaser är Litteraturbanken och Svensk prosafiktion 1800–1900. Dessa används i första hand av litteraturvetare, som i dem kan undersöka olika frågor om exempelvis sociala nätverk i texterna, hur personerna i dem rör sig i rummet och så vidare. Principiellt sett finns det inga hinder för att utnyttja sådana databaser även för mer historievetenskapliga undersökningar, även om det är viktigt att vara medveten om deras begränsningar.[10] (Vi kommer att utveckla resonemanget om betydelsen av kritisk granskning i kapitlets sista avsnitt.)
Fördjupning:
Fjärrläsning och närläsning, stordata och smådata
Bo Pettersson
Fördjupning:
Digitala textarkiv och forskningsfrågor
Mats Malm
Fördjupning:
Kulturomik: Att spana efter språkliga och kulturella förändringar i digitala textarkiv
Lars Borin och Richard Johansson
Noter
[1] Jfr Susan Hockey, ”The History of Humanities Computing”, i Susan Schreibman, Ray Siemens och John Unsworth (red.), A Companion to Digital Humanities (Malden, MA: Blackwell 2004), s. 15, http://www.digitalhumanities.org/companion/ (hämtad 2016-11-14). I en nyutkommen andra upplaga av detta klassiska verk, A New Companion to Digital Humanities (Chichester: Wiley 2016), finns denna historiska översikt inte med.
[2] Se http://endnote.com och http://zotero.org.
[3] Det finns mer information om planering och hantering av forskningsmaterial t.ex. i Handbok för öppen forskning: https://digihist.se/handbok/.
[4] Eftersom det följande i hög grad handlar om text mining och mindre om andra typer av kvantitativa och statistiska studier, bör vi här nämna och framhålla betydelsen av Demografiska databasen i Umeå (http://www.cedar.umu.se/ddb/, hämtad 2016-12-08); den utgjorde en viktig resurs för storskalig demografihistorisk forskning långt innan big data eller digital humaniora blev allmänt använda begrepp.
[5] Jfr Lev Manovich, “The meaning of statistics and digital humanities”, Software Studies 2012-11-27, http://lab.softwarestudies.com/2012/11/the-meaning-of-statistics-and-digital.html (hämtad 2016-12-08).
[6] Om Moretti och distant reading se Kathryn Schulz, “What Is Distant Reading?”, New York Times 2011-06-26, http://www.nytimes.com/2011/06/26/books/review/the-mechanic-muse-what-is-distant-reading.html?pagewanted=all&_r=1& (hämtad 2016-12-08). För exempel på hur resultaten av topic modelling kan se ut se Manovich, “The meaning of statistics”.
[7] Projektet introducerades i en omtalad uppsats i Science: Jean-Baptiste Michel m.fl., ”Quantitative Analysis of Culture Using Millions of Digitized Books”, Science vol. 331 no. 6014 (2011-01-14), s. 176–182, http://www.sciencemag.org/content/331/6014/176.abstract (hämtad 2016-12-05).
[8] Google Books Ngram Viewer, http://books.google.com/ngrams, och Paper Machines, http://papermachines.org (båda hämtade 2016-12-05).
[9] Till exempel finns sådana inslag eller åtminstone potential i flera projekt som kombinerar digitalisering och/eller databasuppbyggnad med egen forskning; bland dessa kan nämnas Gender at work, http://gaw.hist.uu.se/, och Moravian memoirs, http://moravianlives.org/ (hämtade 2016-12-08).
[10] Språkbanken, http://spraakbanken.gu.se; Litteraturbanken, http://litteraturbanken.se; och Svensk prosafiktion 1800–1900, http://spf1800-1900.se (hämtade 2016-12-08).

{kind=link}
Pingback: Databasernas värld – Claudias kursblogg
Pingback: Fördjupning: Kulturomik: Att spana efter språkliga och kulturella förändringar i digitala textarkiv – Historia i en digital värld
Pingback: Kulturomik: Att spana efter språkliga och kulturella förändringar i digitala textarkiv – Historia i en digital värld
Pingback: Fördjupning: Digitala textarkiv och forskningsfrågor – Historia i en digital värld
Pingback: Fördjupning: Fjärrläsning och närläsning, stordata och smådata – Historia i en digital värld
Pingback: Från material till metoder – Historia i en digital värld